
Running Large Scale Services: Operational Excellence
How do you operate your services well


It was 2am on a Sunday in 2015, when my pager at AWS DynamoDB went off. Within minutes, we started to see 100s of alerts and pages. It quickly became clear that the service was having serious trouble.
DynamoDB is a tier-0 service at AWS, a foundational service, that is among the first services to be installed in any new AWS region because every other service depends on it. The incident took us multiple hours to start to recover and almost 4 days to fully get back to normal. It was the largest outage in AWS history!
The war room experience, recovery and the subsequent weeks, months and years working through the post-event operational and scaling issues on one of the largest AWS services (60+ million requests/sec), turned out to be a great learning experience. I still recall my mentor Marco telling me at that time - ‘there are somethings you can only learn through hard knocks’.
Systems usually require re-design when usage grows by orders of magnitude or more. As a rule of thumb, when you build a new system, you should be able to handle one order growth. If you are designing for 2 orders or more, you are probably over-investing upfront. In DynamoDB’s case, the service had grown multiple orders since launch and that led to this event.
Issues are always going to happen - you don’t want to be so risk averse that you stop pushing things out. How much should you invest in Operational excellence? There is no one size fits all answer here. Depending on the stage of your service and customer expectations, you may choose to invest little or a lot at a given point in time.
At DynamoDB and Lambda , we invested in two areas to help us keep operational pace:
Building a culture of Operational Excellence in our teams, where we learn from incidents, share learnings and incorporate actions to prevent similar issues in future.
Investing in building ways to detect issues and recover as quickly as possible.
Operational Excellence Culture
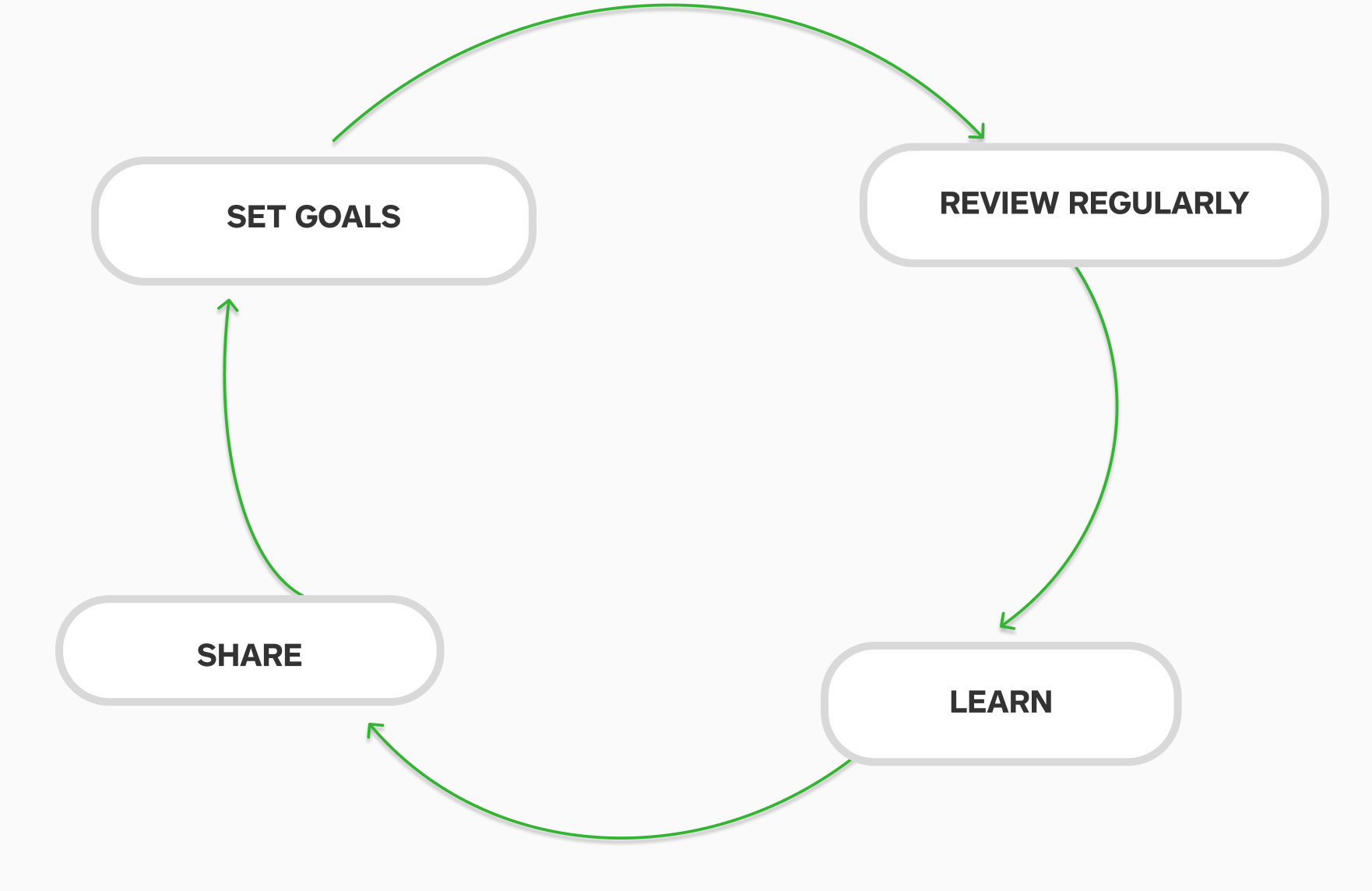
Set up operational/SLA goals for services: All services in AWS take SLA goals e.g. availability. This helps them make tradeoffs between an operational investment (e.g. active-active database) vs a feature investment. How did we set operational goals? These goals are typically set as a combination of business needs and demands that would place on team operationally. For e.g. early on in Lambda we started with SLA of 99% based on business acceptability and pager load it would place on teams.
Regular Operational Reviews in your teams: Service leaders review operational performance across their teams weekly. It helps them stay close to the ground and also reinforces that operations matter.
Learn from Operational Incidents: Every operational event is an opportunity to improve. Conduct a Post Mortem and take actions. For e.g. by looking across many incidents, we found that significant % of our incidents were triggered by deployments. Unsurprisingly, the most common mitigation step is to roll back. This led to an audit step for deployments that teams had to answer - Can you safely roll back what you are about to deploy?
Share learnings: AWS runs a weekly operational review every Wednesday across all services. It is a forum to share learnings and best practices across teams. In the meeting, teams share successes, review key operational events and review service metrics for 1–2 services - chosen at random by spinning a wheel.
Detecting Issues and Recovering Quickly
Invest in identifying issues as early in lifecycle: While the mechanisms that you choose may vary, the key principle is that the cost of fixing an issue goes up by order of magnitude as you go from your dev machine to each subsequent step.
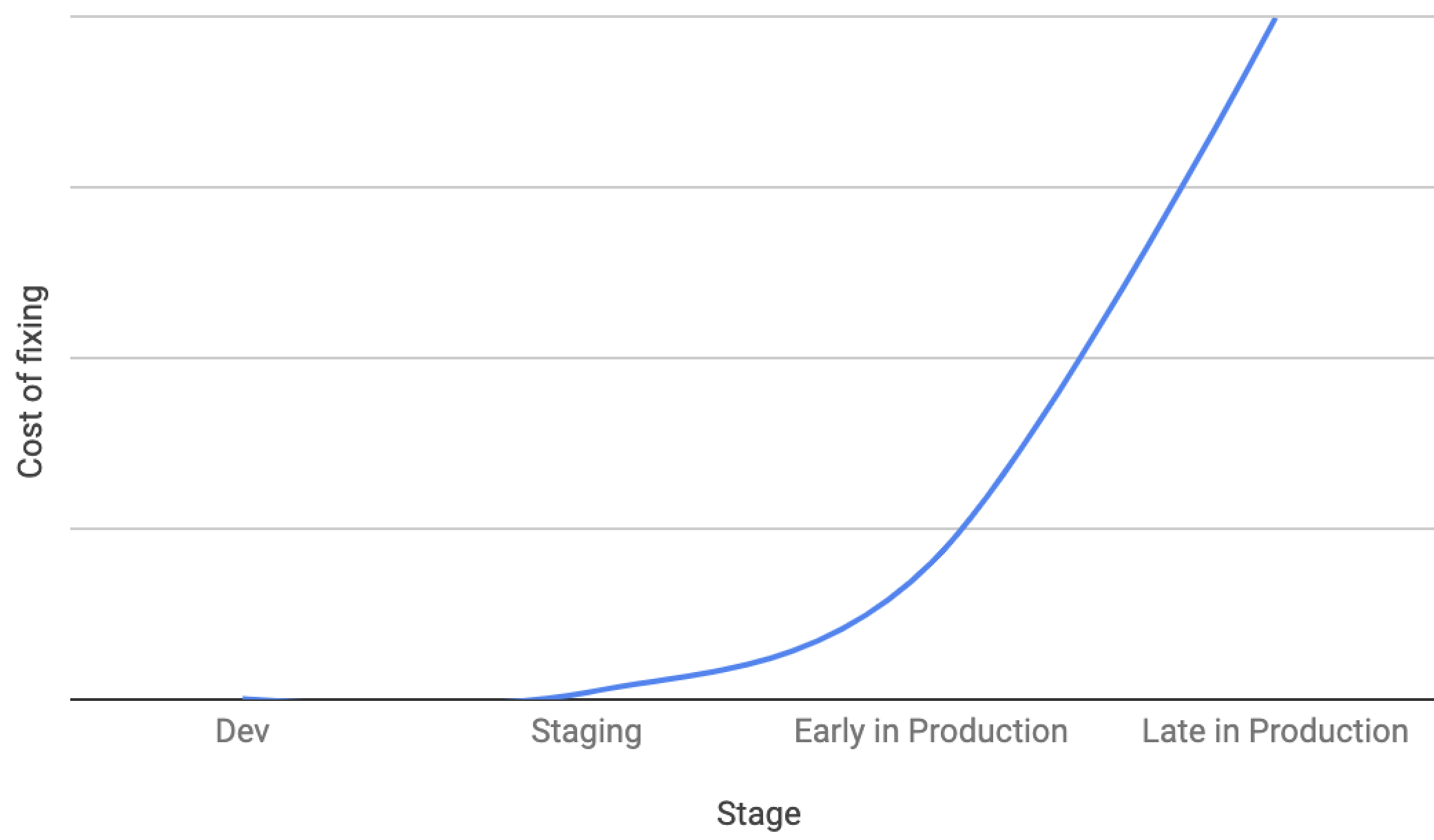
As a result, invest in systems that catch issues earlier in that cycle - e.g. automated tests in staging or canaries on production or doing a limited rollout in production. In AWS for e.g. we deploy first to a ‘onebox’ and monitor its metrics.
Reducing Mean Time to Detect: Similar to above, mean times to detect (and therefore recover) are typically an order of magnitude higher as they go from automated detection.
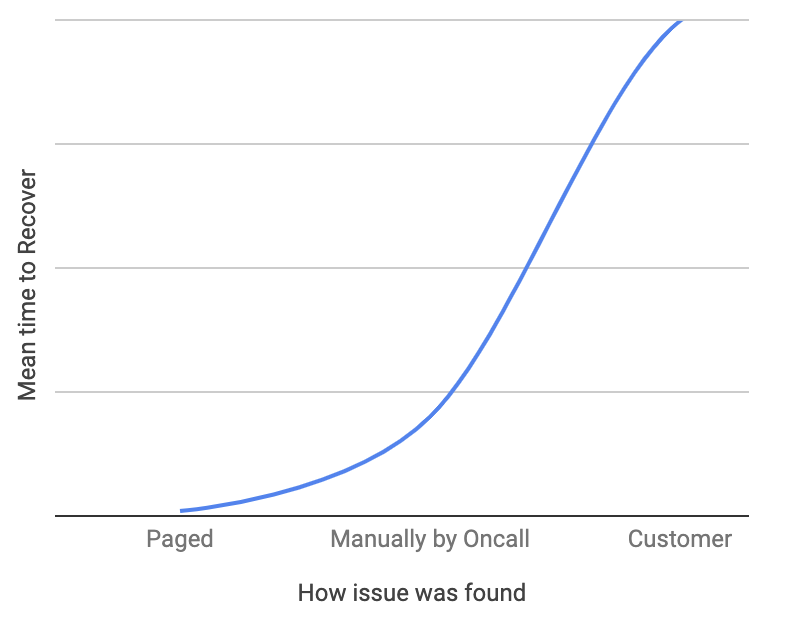
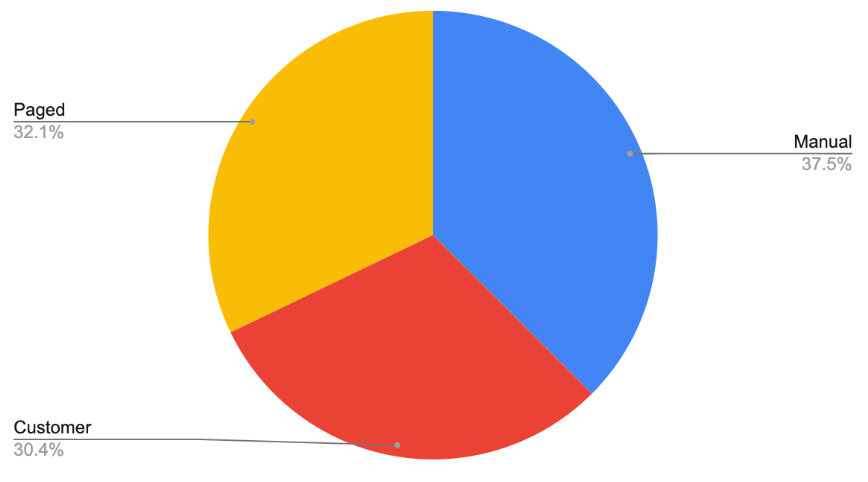
As a result, investments in proactive alarming will make a huge difference e.g. having headroom graphs in your dashboard and alarming at 75% capacity could prevent a bad capacity issue on production. Take a look at your team’s incidents from the past months and see what percent were manually discovered and start putting in alarms to bring that number down.
What should you monitor? Here is a great tutorial on how teams at AWS do monitoring and setup dashboards.

Good one. Just for fun you could have mapped the learnings to your ‘5 whys’